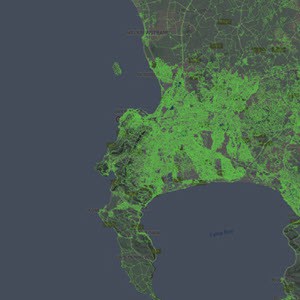
"Highly visual, LEGION makes it easy to validate and adjust, if necessary, the design and relevance of the redevelopment project."
“CUBE - As the name suggests, it provides a multidimensional approach in developing and editing the models, making it easier to work on for modelers across the world.”
“The DTA Model is an effective tool to evaluate traffic diversion impact due to network supply capacity changes and the model results are credible and highly recognized by the City Council and transportation professionals.”